voice
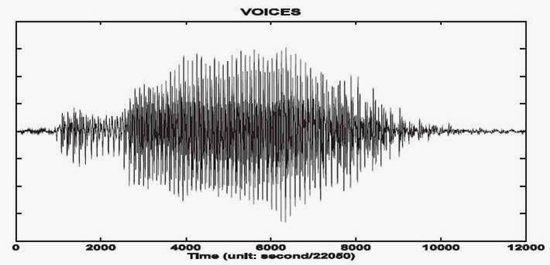
The original data, given in Figure 1, shows the digitalized sound of the word, “Hello,” at 22,050Hz digitization. This data was processed with the ensemble empirical mode decomposition method (EEMD) with a noise selected at an amplitude of 0.1 times that of the data root mean square value (RMS), and 1000 trials. The result is shown in Figure 2. Here, all the IMF-like components are continuous and without any obvious fragmentation. The third component is almost the full signal, which can produce a sound that is clear and with almost the original audio quality. All other components also have relatively uniform scales, but the sounds produced by them are not intelligible: they mostly consist of either high-frequency hissing or low-frequency moaning. The results clearly demonstrate that the EEMD has the capability of catching the essence of data that manifests the underlying physics.
|
| Figure 1 "Hello" sound digitalized at 22,50Hz. |
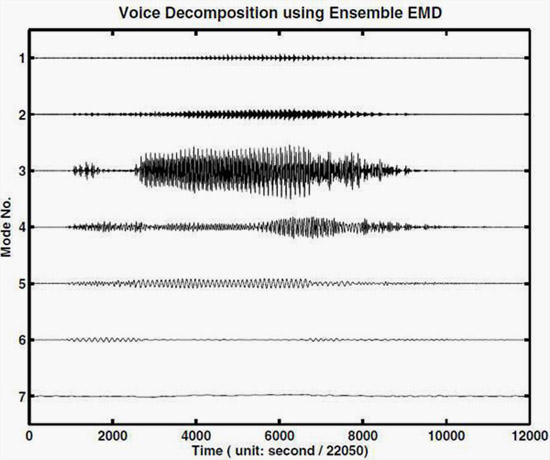 |
| Figure 2 EEMD result of "Hello" sound |
The Hilbert spectrum from the EEMD is shown in Figure 3. All basic frequency traces are continuous in the time–frequency space. There is no mode mixing and frequency gaps. This implies that the adaptive representation may be a better choice to represent the essence of voice and the popular harmonic representation of voice.
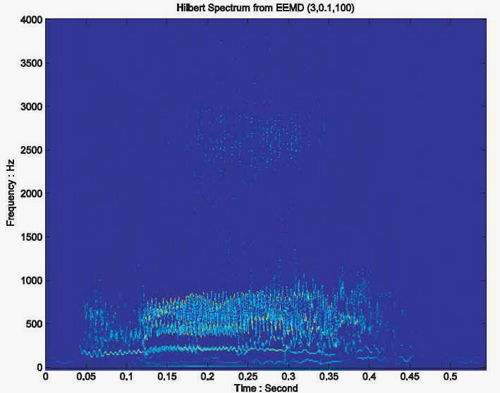 |
| Figure 3 Hilbert Spectrum of "Hello" sound. |